Post-Processing of data from Precipitation HTC¶
This example demonstrates how to use PanPython SDK handling the raw data from HTC precipitation simulation and perform statistical analysis of these data. In this example, raw data are commingled in two merged CSV files (Default.table.csv and generated.table.csv) and a JSON file containing HTC conditions. The merged files are then visualized through a Jupyter notebook.
Precipitation HTC is discussed in Parallel High-Throughput Precipitation Calculation (HTC)
About precipitation HTC¶
Precipitation HTC allows a user to perform simulations for numerous compositions/heat treatments in the user-defined state space by a simple setting. Alloy compositions and heat treatment conditions that satisfy user-defined criteria can then be identified through data mining of the simulated results.
A step-by-step guide¶
Note
A video guide will be available very soon.
- Open the demo folder
“/Solution Examples/panhtc_precipitation_post_process/” from PyCharm IDE. See Installation to setup the IDE environment.
- Build a task script
An example script panhtc_precipitation_post_process.py has already been include. Following the steps the create your script:
- Import packages
from panpython.sdk.stat.htc_result_post_processing import PandatHTCResultProcessor import os
- Setup working folders and input files:
dir_name = os.path.abspath(__file__) file_name = os.path.basename(__file__) task_path = dir_name[:-len(file_name)] htc_result_parent_path = 'source/default'
- Setup table name of each point calculation:
file_name = ['Table/Default.table', 'Table/generated.table']
- Setup output path
dump_path = os.path.join(task_path, 'output')
- Run post-processing of point HTC:
if __name__ == "__main__": htc_condition_dict = PandatHTCResultProcessor.htc_condition_dict_creator( cal_type='precipitation', parent_path=htc_result_parent_path, output_path=dump_path) for f in file_name: m_processor = PandatHTCResultProcessor(parent_path=htc_result_parent_path, file_name=f, cal_type='precipitation') m_processor.save_to_csv(output_path=dump_path, output_file='')
- Run the post-processing script
After the post-processing is finished, two csv files (Default.table.csv and generated.table.csv) and a JSON file (htc_condition.json) is ready to be used. See The inputs and outputs of this post-processing task for details.
Visualize post-processed data¶
An example Jupyter notebook panhtc_precipitation_post_process.ipynb has already been included. Run it through terminal:
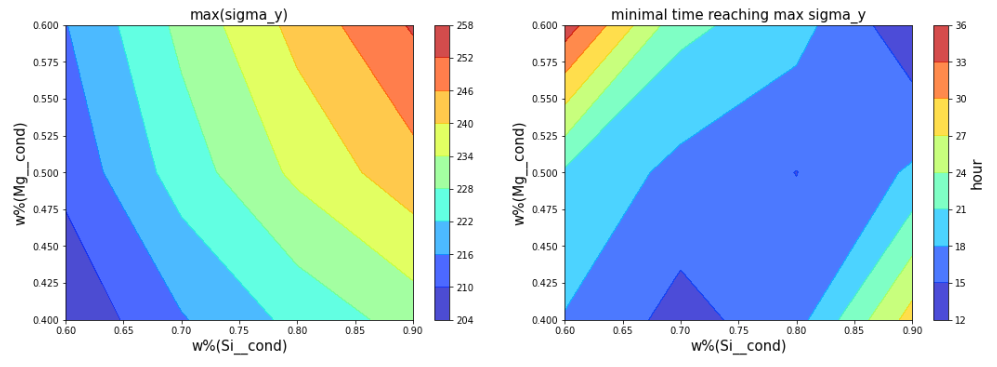
>jupyter notebook panhtc_precipitation_post_process.ipynbThe first plot from the notebook contains two figures. The left-hand figure is a color map of max yield strength among heat treatment temperatures. And the right-hand figure is a color map of the minimal time when the max yield strength is reached at a given composition.
The next plot from the notebook is an interactive color map of max yield strength among heat treatment temperatures. User can assign heat treatment time through the range bar to explore yield strength’s dependence.
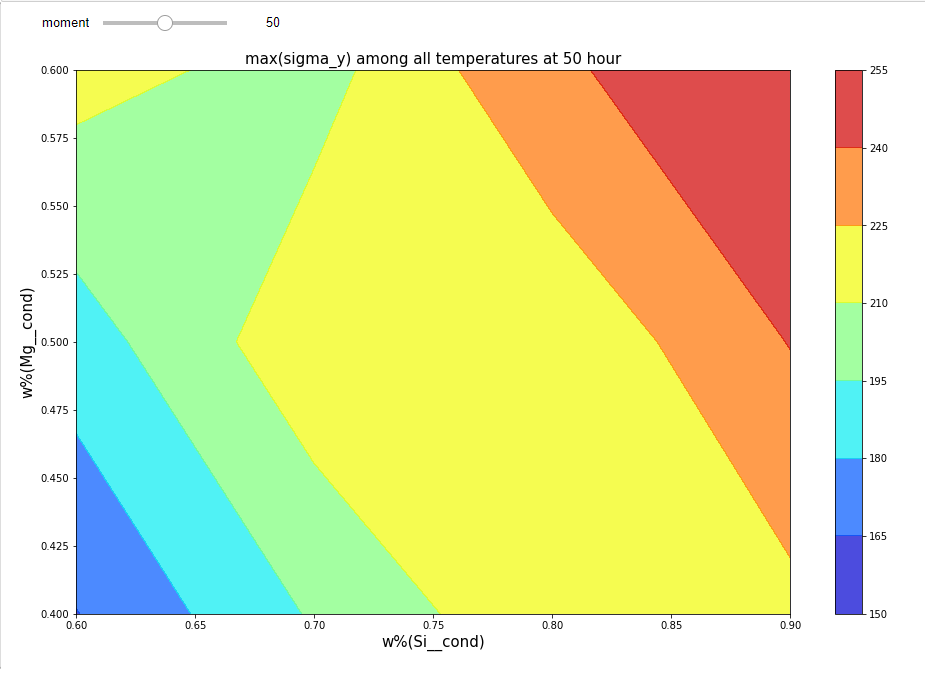
Run through the notebook, and click “Display/Refresh” button, an interactive plot will be displayed:

See details about this interactive plot in section Visualize post-processed data of Post-Processing of data from Point HTC.
The inputs and outputs of this post-processing task¶
The following figure displays inputs and outputs of this post-processing task.
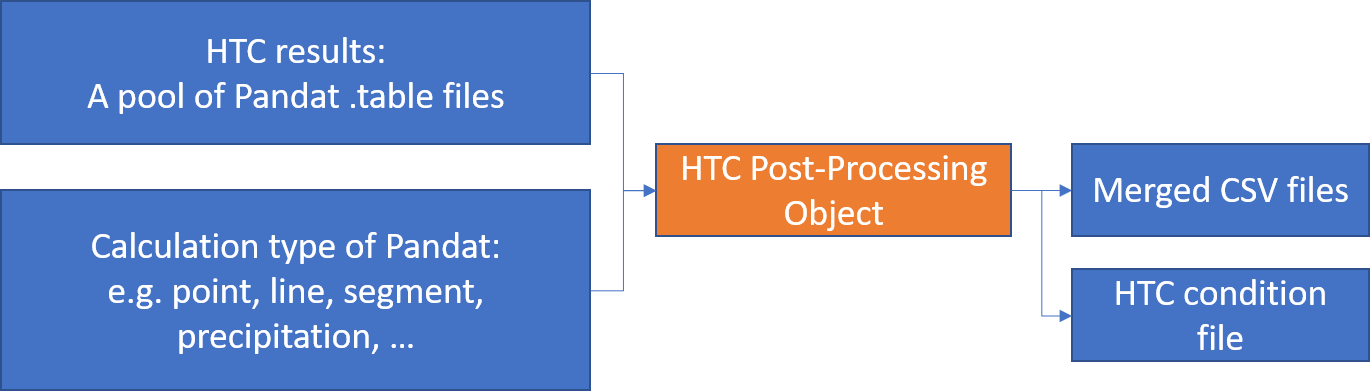
- File structure
The follow diagram displays the file structure used by this post-processing task:
Note
The “resource” folder is a copy of Pandat workspace. See details of Pandat workspace in Chapter 2.1 of Pandat Manual: .
panhtc_precipitation_post_process |- output # outputs | |- Default.table.csv # A CSV file containing combined results of all Default.table files | |- generated.table.csv # A CSV file containing combined results of all generated.table files | └─ htc_condition.json # A JSON file describing HTC condition └─ resource # a copy of Pandat workspace folder └─ default # The parent folder containing all HTC points └─ Precipitation Simulation_PX_X # The child folder (id: PX_X) of precipitation calculation └─ Table # The folder containing .table file |- Default.table # the default .table file from a Pandat calculation └─ generated.table # the generated .table file from a Pandat calculation
- Inputs
The input files are under /resource folder.
resource/default/Precipitation Simulation_PX_X/Table/Default.table: A Pandat .table file containing a precipitation calculation result with default columns.
resource/default/Precipitation Simulation_PX_X/Table/generated.table: A Pandat .table file containing a precipitation calculation result with customized columns.
- Outputs
The output files are under /output folder.
Default.table.csv: A CSV file containing combined results of all Default.table files
generated.table.csv: A CSV file containing combined results of all generated.table files
htc_condition.json: A JSON file describing HTC condition. See details of this file in HTC condition JSON file.
HTC condition JSON file¶
Every single calculation of HTC has its own condition. The condition together with its task id are stored in the HTC condition JSON file.
The PanPython API will use task id to query condition when performing statistical analysis and visualization
The structure of this HTC condition JSON file is visualized using https://jsonviewer.io/:
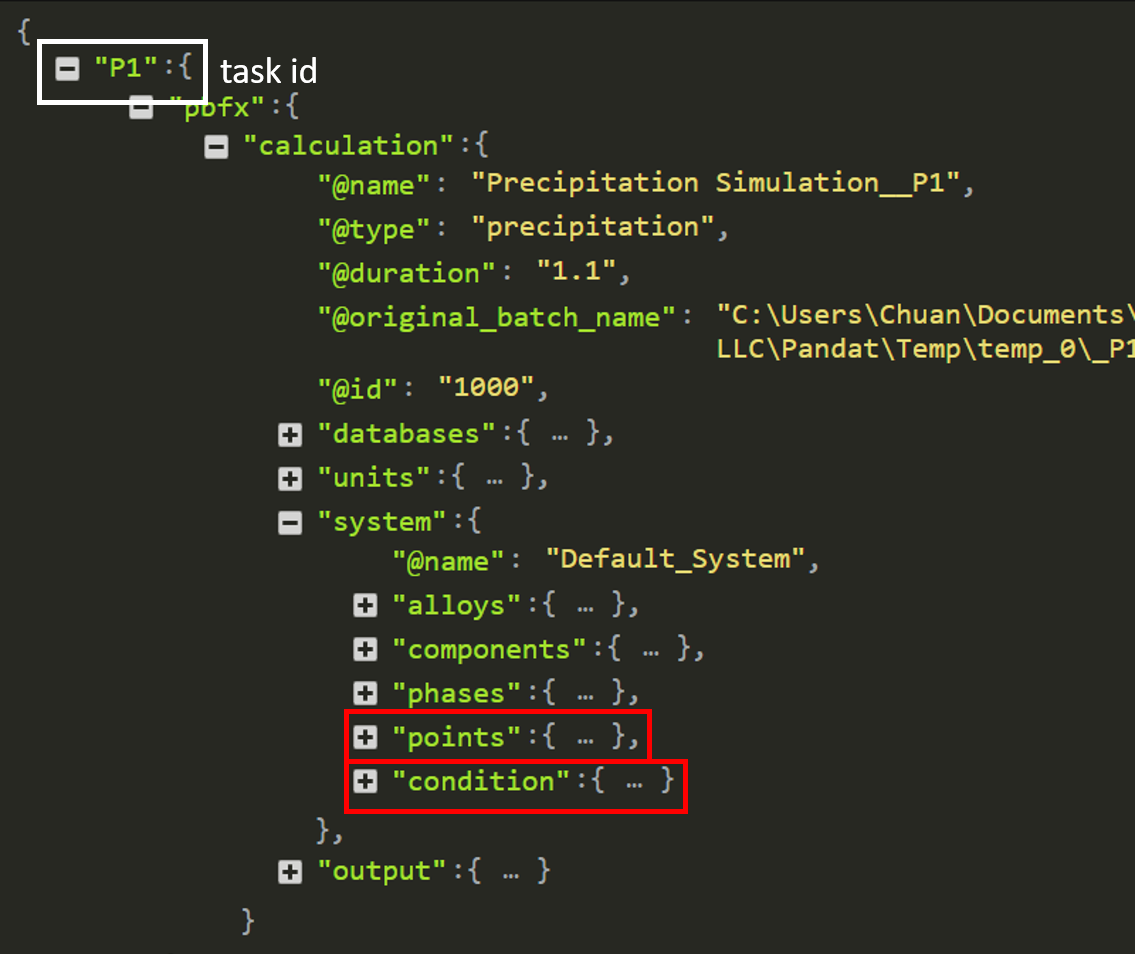
After expanding points node, the composition of this calculation is displayed

After expanding condition node, the thermal history of this calculation is displayed
